· Mick Hua · build-log · 9 min read
From Notebooks to Production: Building Data Pipelines with Multi-Agent AI
How we used specialized AI agents to convert messy data science notebooks into production pipelines, and the lessons we learned about agent validation, context management, and preventing shortcuts.

The Problem
Our data science team had built a look-alike analysis model, a system that takes our data and uses it to segment another company’s data. The prototype was a collection of Jupyter notebooks and SQL files. We needed to productionize this into a proper dbt pipeline, and manual conversion would have taken weeks.
What is dbt? dbt (data build tool) is an open-source framework that helps data teams transform data in their warehouse using SQL. Think of it as a way to turn messy SQL scripts into organized, testable, production-ready pipelines.
The real challenge wasn’t just the code volume. It was the signal-to-noise ratio. Legacy code, experimental dead ends, and debugging artifacts were scattered throughout, acting as red herrings that could mislead any AI agent trying to extract the actual pipeline logic.
Start with Evaluation: How Will You Know It Works?
Before writing a single line of agent code, we needed to answer one question:
How will we know if this actually works?
We were lucky here. There was a concrete way to validate: test that the outputs match the model the data science team had already built. That quickly became our north star.
But having a clear validation target doesn’t mean you can skip testing. I still did extensive testing because this was a proof-of-concept that agents could handle real production work with the right guidance. It needed to be airtight.
Building a Multi-Agent System
I’d built multi-agent systems before in personal projects, so I had a sense of what could work here.
The architecture I designed had dedicated, specialized agents:
- dbt Model Builder: Focused on converting notebooks and SQL into dbt models
- Testing Agent: Validated outputs and ran tests
- GCP Agent: Handled all Google Cloud Platform (GCP) interactions
- Planner Agent: The primary Claude session that orchestrated everything
Context Workflows and Manifest Files
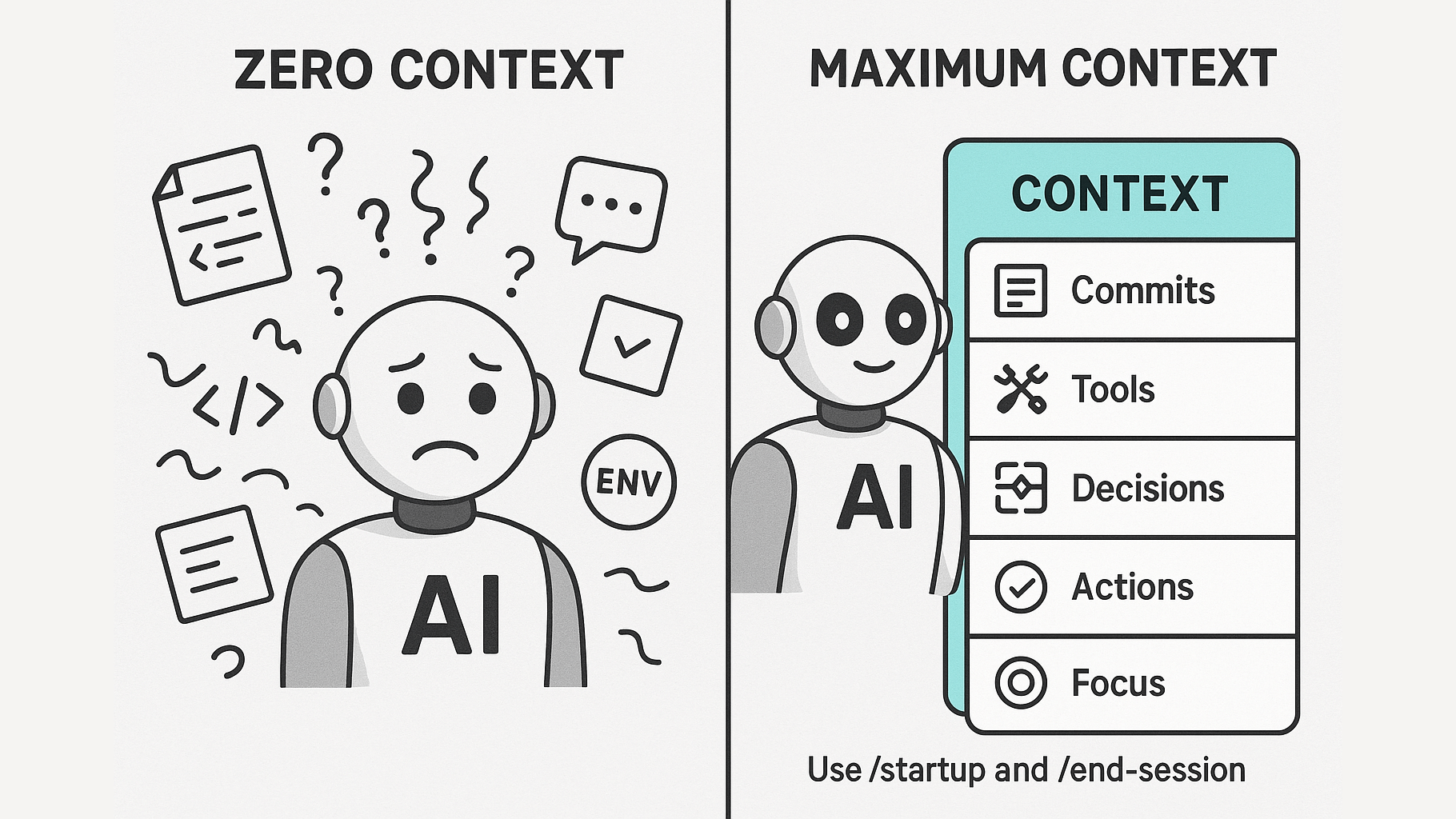
The key innovation was routing agents to specific context files depending on what they needed to do. Each agent got exactly the context it needed—nothing more, nothing less.
To make this work at scale with a messy legacy codebase, I built what I call manifest files. These don’t contain the actual content—they route to it. Think of them like a dictionary or index: specific file paths and line numbers pointing you to exactly where you need to look.
This was crucial for managing context. Instead of dumping entire notebooks into an agent’s context window, the manifest would point the agent to exactly which file and which lines contained the relevant logic. The agent could then pull just what it needed.
Before deploying the system, I blind tested each agent to make sure it could do what I expected and to identify friction points so guidelines could be refined.
Building Trust Iteratively: Shadowing Like a Junior Engineer
Once the system was set up and agents could handle tasks within their specialization, I didn’t just let them loose on the entire project. I took an iterative approach, building confidence gradually with each step.
The first milestone? Getting the system to build a single dbt model. That’s it.
I had agents output their decisions and actions to a log so I could monitor what they were doing—sort of like shadowing a junior engineer to see if they’ve understood your guidance at a base level and aren’t just parroting your instructions.
Once I had confidence they could handle that, I increased the responsibility:
Can the agent build 2 models? Can it validate the output table against the existing model the data science team built?
Each increment built more trust. By the end, the agents were operating with real autonomy because I’d proven to myself they understood the work, not just the instructions.
Custom Tooling: Offloading Friction to Deterministic Code
As I tested the agents, friction points emerged. The biggest one? GCP authentication. Agents would consistently get bogged down in credentials and API setup.
The solution was to build custom tooling that offloaded these mechanical tasks to deterministic code. I created wrappers around the existing GCP SDKs that handled all the authentication complexity. Agents could focus purely on writing query logic, then the workflow would automatically route them to use the GCP tooling.
This pattern worked brilliantly: identify where agents struggle with mechanical tasks, then build tooling that lets them focus on the creative problem solving they’re actually good at.
The Red Herring Problem
The biggest struggle wasn’t the tech itself—it was figuring out what was real and what wasn’t. The legacy notebooks and SQL files contained:
- Experimental code that never made production
- Multiple approaches to the same problem
- Debugging artifacts that looked like features
- Code that wasn’t relevant to the actual pipeline at all
Agents would latch onto these red herrings and try to incorporate irrelevant patterns into the dbt models. We spent significant time going back and forth with the data science team, figuring out what was signal and what was noise.
My takeaway: Clear out the noise before you point agents at the code. Would it have worked without this cleanup? I don’t know—but agent performance was noticeably better with a cleaner codebase.
Preventing Reward Hacking
What is reward hacking? When AI agents find shortcuts to appear successful on tests without actually solving the underlying problem. For example, hardcoding expected values instead of implementing real logic.
This was my biggest concern. I’d seen agents reward hack in my personal projects, so I was most concerned the agents would do this here by manufacturing or hard-coding values instead of actually solving the problem.
Our Defense Strategy
1. Agent Diversity The more you spread work across different agents, the less likely they are to reward hack. Reward hacking mostly happens with a single agent over very long sessions. We used multiple agents for different pipeline stages—if one agent cut corners, another would likely catch it.
2. Cross-Validation We had separate agents validate outputs. One agent builds, another reviews. They don’t share context about what shortcuts might work.
3. Input Mutation Testing The killer test: we changed the input data without telling the agents. If the pipeline had hard-coded values or hacked its way to results, changing inputs would expose it immediately.
The agents had no idea this validation was happening in parallel, so there was no way to game it. We tested with the original dataset, mutated the data to ensure outputs changed predictably, then compared against the data science team’s validated pipeline.
4. Manual Spot Checks At each iteration, we physically inspected what the agents produced. Sometimes agents would build whole models that weren’t relevant—but that wasn’t their fault. The notebooks and SQL files the data science team provided included testing code, old iterations, and experimental work mixed in with the production logic. The agents were just doing what they were told based on what they could see.
Why This Would Have Been Nearly Impossible Without Agents
Doing this manually would have been brutal. I would have had to review every single line of code and every red herring the data science team had provided. More importantly, I would have needed to understand in detail the DS team’s model logic before even starting the conversion.
That traditional approach would have meant spending weeks just on comprehension. Reading through hundreds of lines of notebooks and SQL, trying to map out what was actually production logic versus what was exploratory work.
With agents, we still developed understanding, but it happened as we built, in collaboration with the DS team, rather than focusing on very specific details upfront. I also used agents to interrogate what the DS team had built. Getting across hundreds of lines of code was done in a day, not two weeks.
The agents compressed the learning curve. Instead of having to become an expert in their model before writing a single line of dbt, I could learn iteratively while building. The agents handled the tedious work of parsing through the noise, and I focused on validating the signal.
Results
We got the look-alike analysis model into production as a proper dbt pipeline in a fraction of the time manual conversion would have taken. The pipeline works, passes validation against the data science team’s reference implementation, and handles input variations correctly.
Are the agent-built dbt models perfect? No. There are still spots where noise crept in. But they’re production ready and maintainable, which is what matters.
Lessons Learned
Start with evaluation, not implementation - Define concrete validation criteria before building anything. Having the data science team’s reference implementation as a north star was critical.
Specialized agents with context workflows scale better than monolithic sessions - Give each agent access to exactly the context it needs, nothing more. Manifest files that route to content rather than containing it are key to managing context efficiently.
Offload mechanical friction to deterministic code - Agents excel at creative problem solving but struggle with mechanical tasks like authentication. Build custom tooling for the latter.
Blind test your agents before deployment - Testing each agent individually reveals friction points early and lets you refine guidelines before going to production.
Build trust iteratively like training a junior engineer - Start small (one model), monitor decisions through logs (not just outputs), then gradually increase responsibility. This shadowing approach reveals whether agents understand the work or are just parroting instructions.
Noise reduction matters more than I expected - Clean, focused codebases give agents better results than clever prompting on messy code.
Multi-agent validation catches shortcuts - Single agents over long sessions are prone to reward hacking; diverse agents validate each other.
Trust, but verify with mutation testing - Changing inputs without the agent’s knowledge is the most reliable way to catch hard-coded or manufactured results.
Collaboration beats automation - The back-and-forth with the data science team to identify signal vs. noise was essential.
The multi-agent system did the heavy lifting. The hard part was teaching them what to ignore.
Connect with Mick
If you’d like to connect you can find me on LinkedIn.
- Get Involved Want to share your story? Get involved to share how you build.
- Subscribe: newsletter.howibuild.ai/subscribe