· Tabish Bidiwale · build-log · 7 min read
Go slow to go fast!
Why planning with AI matters more than ever, and how to stop stumbling when you’re building with LLMs.

Here’s the thing: there’s never been a better time to be building, whether it’s tinder for dogs or something world changing. Yet with all this power in the palm of our hands, we’re still stumbling.
AI lets us build faster than ever before, and still we hear the same complaints:
- “That’s not what I asked for…”
- “Why did you add that?”
- “This is way too complex…”
- “You forgot to…”
We blame the tool: AI slop, context rot, prompt hell.
But the truth is this is less about the tool, and more about how we are using it.
It reminds me of the saying A tradesman never blames his tools 🛠️
Who am I?
Wait, you’re probably wondering who’s this guy?
I’m Tabish. I’ve been a dev for 6+ years. I like Formula 1, Seinfeld and Arrested Development quotes, and I build tools for myself and other devs.
I’ve been deep into AI since Sonnet 3.5 came out, which was the first model that (in my opinion) gave us a real glimpse of what AI-assisted programming could become.
More recently, I released an open-source project called OpenSpec. It helps devs everywhere get better alignment and results from their coding assistants by working through specs.
It had a mini-viral moment, hitting the top of r/cursor and pulling in nearly 400 stars in its first week. But more on the tool later!
Why we keep tripping up
Software engineering has always been about working within constraints. Building with LLMs is no different. It is a game of squeezing out the best performance so we can ship to production, not just prototypes.
Like most skills, this takes practice. Geoff Huntley, a fellow Aussie, describes it like learning to play an instrument. You get better over time, but it takes deliberate, intentional practice.
The good news is many of the habits that make coding agents work better are the same ones we have known in traditional software engineering for years. We just forget them because when you are handed a rocket ship, who stops to plan the flight path? 🚀
What doesn’t work
Before we talk about what works, let’s call out the traps:
- ❌ Trying to build an entire app in a single chat
- ❌ Not breaking work into smaller, testable units
- ❌ Skipping research
- ❌ Not understanding what you are trying to build
The common thread is bad alignment and bad context.
Think about how you would mentor a junior engineer. What background, requirements, and scaffolding would they need to succeed? LLMs are no different. The bigger the task, the more structure they need.
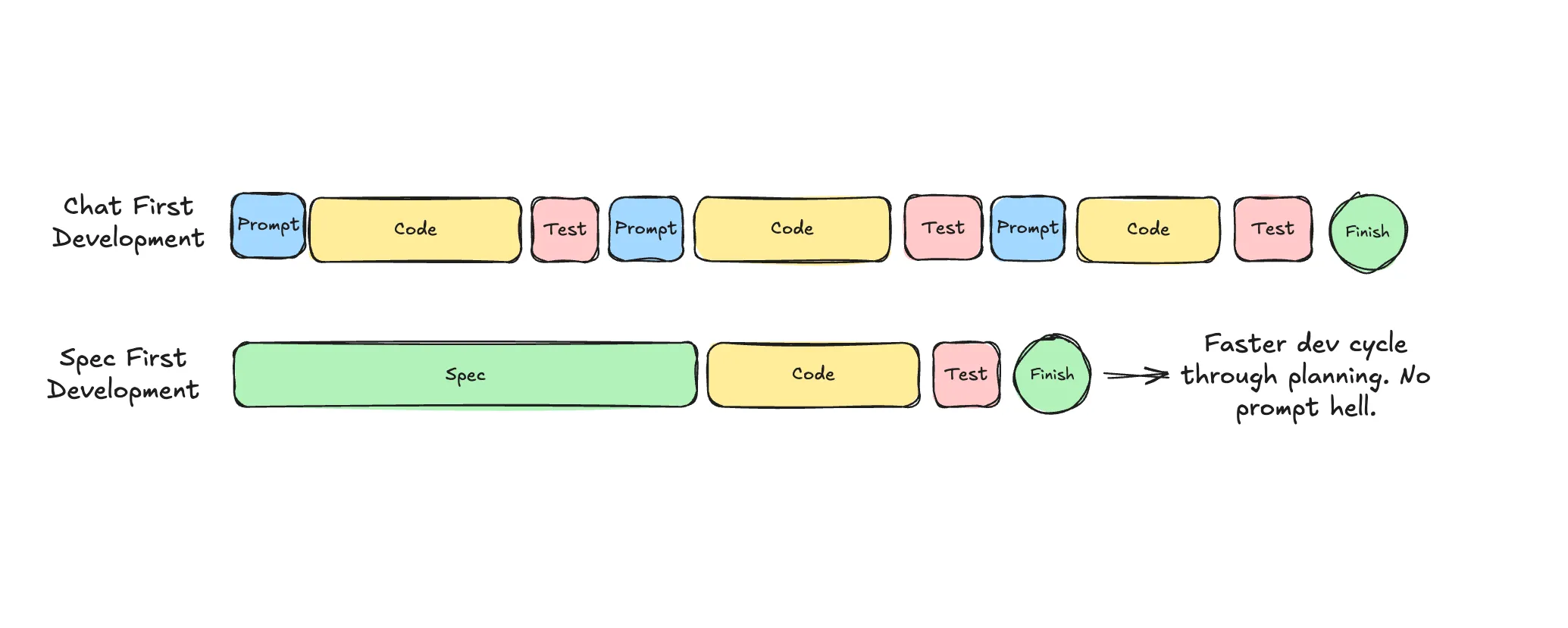
The simplest loop
Forget the frameworks and prompt templates for a second. Let’s go back to basics.
For small fixes like a bug or a function, just prompt the agent directly. Most modern models can handle that.
But for bigger tasks, here is the simplest loop that works:
Research → Plan → Implement
Research
Get the model to gather docs, confirm library versions, collect examples. Output it all to a file likeresearch.md.Plan
Break things down into phases and steps. Write clear success criteria. Make the implicit explicit.Implement
Use the plan as scaffolding. Implement one testable phase at a time. Keep sessions small. Reset often.
That is it. That minimal scaffolding turns your chat toy into a real partner.
The next level up: Specs
Planning is good, but it only explains how you will do something. To actually get what you want, you need to clarify what you are building.
That is where specs come in. Specs define:
- ✅ What is in scope and what is out of scope
- ✅ What matters and what does not
- ✅ Acceptance criteria and non-goals
- ✅ Constraints, interfaces, edge cases
Specs are the highest leverage part of the pipeline:
- 👉 Get the spec right and research gets easier
- 👉 Get research right and plans get sharper
- 👉 Get plans right and implementation becomes simple execution
Start at the top and you cascade success. Get it wrong and you cascade failure.
And here is the kicker: do not just ask AI to generate specs or plans and walk away.
This is where your brain matters most! It is way easier to debate a 500 lines of spec than review 5,000 lines of code.
If you spend effort anywhere, spend it here.
Enough theory, let’s put it into practice
So, does this actually work in practice, or is it just nice on paper?
I’ve been using spec-driven development exclusively while building OpenSpec itself. Yes, it’s meta: I’m using a spec-driven tool to build a spec-driven tool. But that’s exactly why it’s the best possible proof that the methodology holds up.
You don’t have to take my word for it. All of OpenSpec’s specs and their entire history are public on GitHub. You can trace the evolution of the project from idea to implementation:
👉 OpenSpec change history
Walking through a real example
Every major feature in OpenSpec starts the same way: with a change proposal.
Here’s a recent one: a user requested integration with their tool of choice, Kilo Code.
To kick things off, I prompted the system:
Me: Research how Kilo Code implements custom slash commands. Then create a "change proposal" that extends OpenSpec to support Kilo Code.OpenSpec generated a proposal.md file summarizing the idea:
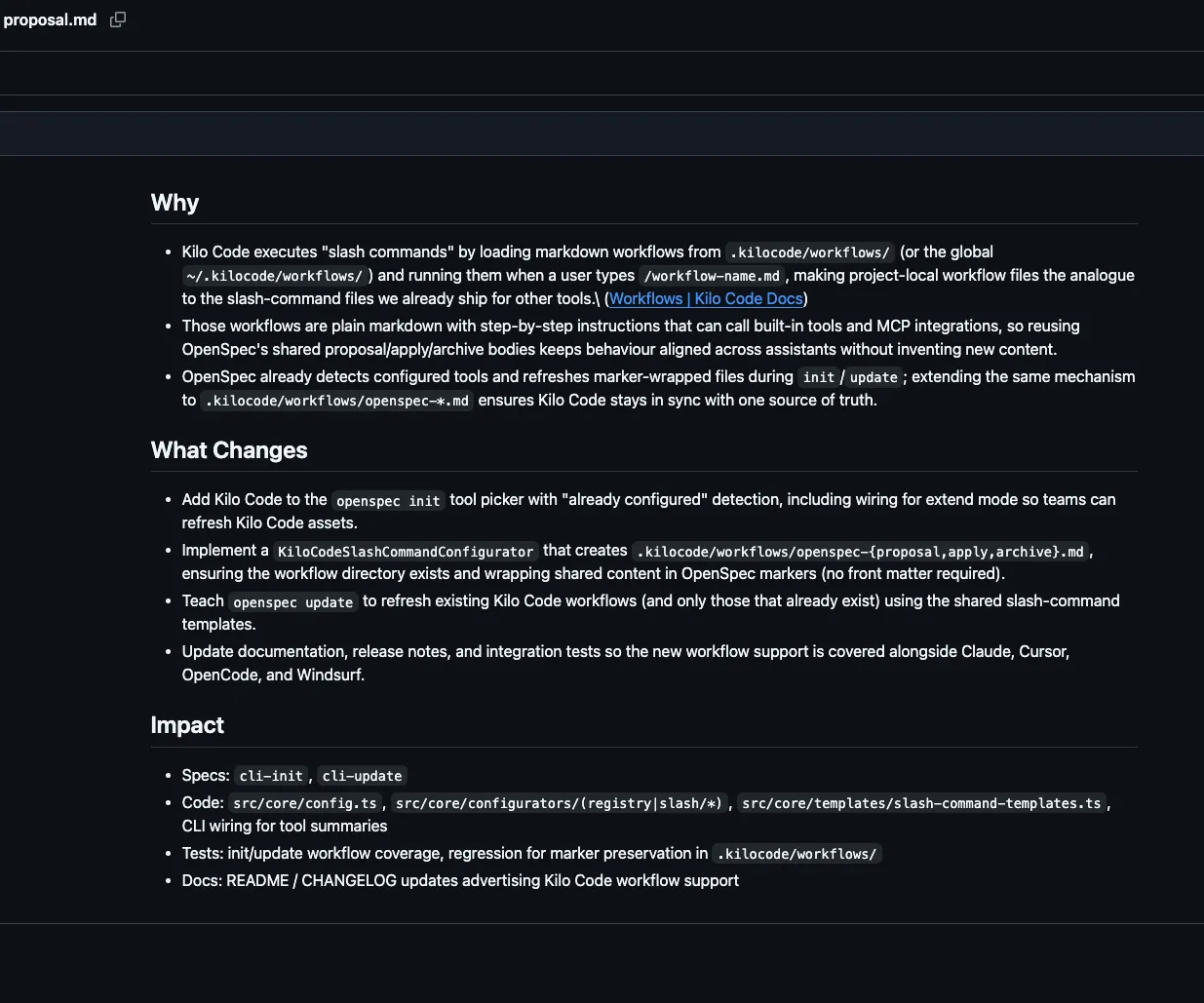
Breaking down the proposal
The proposal highlights which specs are impacted:
Impact
Specs: cli-init, cli-updateThis makes sense. We want users to be able to add the integration during openspec init and update it later via openspec update.
It also shows the exact modified requirement, so I can review whether the change matches expectations:
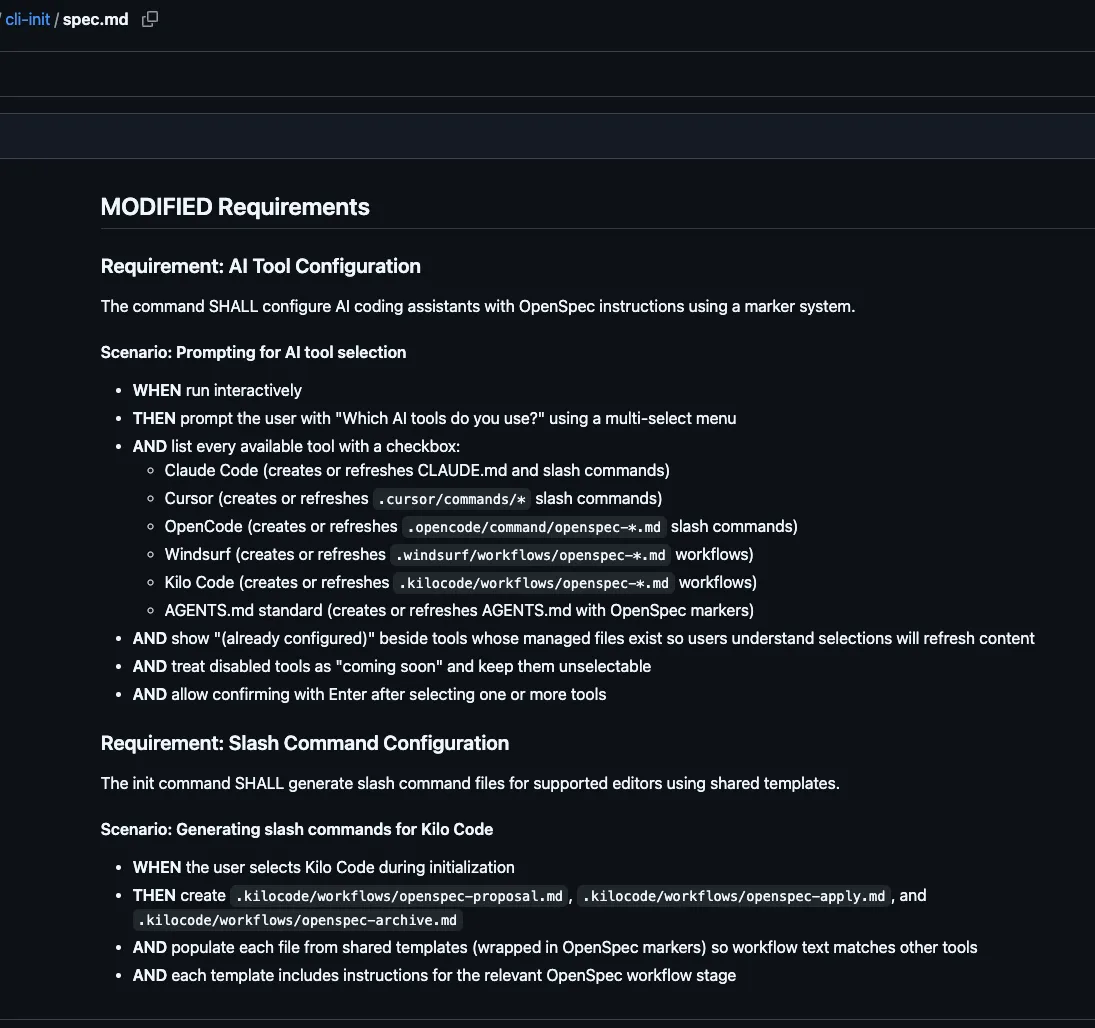
Finally, a tasks.md file is generated, breaking the work into clear, step-by-step tasks:
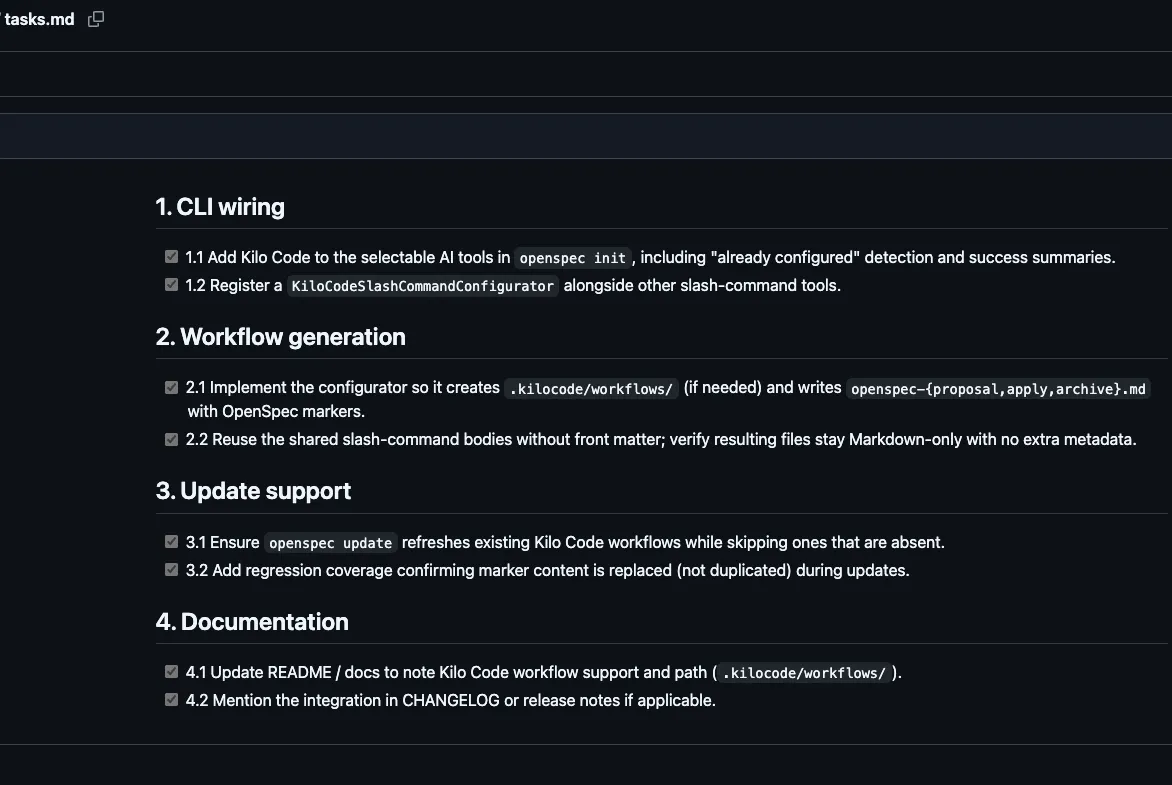
From proposal to implementation
At this point, the only thing left is to implement.
By feeding the reviewed spec into my dev tools (codex-cli + gpt-5-codex-high), I had the integration working on the first attempt.
Why? Because I had already reviewed and verified the spec up front. For example, I caught that Kilo Code stores workflows in a different location than what the AI had suggested. Fixing that early saved me from endless prompt-tweaking and rework.
The result: no prompt hell, no wasted cycles, just a clean first-try implementation.
Other useful patterns to speed up development
Fail fast, learn fast
Do not get precious with code. Try three small versions of an idea. Note what worked and what failed. Feed that back in. I often start big projects with scrappy prototypes, and after that the spec and plan practically write themselves.
Version control hygiene
When you ship faster, hygiene matters more. Branch often. Commit often. Use worktrees. Make it easy to throw code away and roll back.
Pick the right model for the job
- High reasoning models like Claude 4.1 Opus, GPT-5-high and Gemini 2.5 Pro for planning and design.
- Fast execution models like Claude 4.5 Sonnet, Grok Code Fast and Gemini 2.5 Flash for boilerplate and refactors.
Match tool to task. (Though to be honest I rely on high reasoning models for both planning and implementation, as it works well for me).
Manage session context like your life depends on it
Ever notice how LLMs are sharpest at the start of a session? That is context rot. Ignore the marketing, your “1M token context window” is rarely all usable. LLMs aren’t too different from humans in that regard, the longer they work in one continuous session the more tired they get and higher risk they’ll make mistakes. Reset often.
Be careful with MCP tools
They are powerful, but every tool definition eats into your usable context. Do not bloat your sessions. Strategically toggle them on and off to minimise token usage and maximise impact.
Closing
“Go slow to go fast” is not about slowing your pace. It is about deliberate scaffolding.
Specs, research, plans, alignment.
Build those in and you stop stumbling. You turn AI from an intern who “doesn’t get it” into a true collaborator. And that is how you actually go fast.
If you’d like to connect you can find me on LinkedIn.
Check out my project OpenSpec that puts the above into action by helping you shape your specs early.
- Get Involved Want to share your story? Get involved to share how you build.
- Subscribe: newsletter.howibuild.ai/subscribe